

Over the past year, OpenAI has been secretly changing ChatGPT.
Researchers from Stanford and UC Berkley found that the behavior of ChatGPT changed significantly between March and June 2023, despite ChatGPT being marketed as the exact same product to customers.
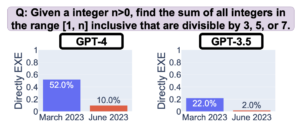
Source: https://arxiv.org/abs/2307.09009
In some cases, this has resulted in the model performing worse. At the heart of this issue is a lack of transparency from OpenAI. Customers deserve to know when models are being trained, modified, and deployed.
OpenAI isn’t alone in this. The Foundation Model Transparency Index recently found that “No major foundation model developer is close to providing adequate transparency, revealing a fundamental lack of transparency in the AI industry.” Given the importance of this technology, it is utterly inexcusable that AI labs are refusing to be honest with the public about what they are building.
The dangers of a lack of transparency go far beyond misleading customers with worsening performance of the model. Many AI labs refuse to discuss the data that they use to train their models (which likely includes copyrighted materials and personal information) or the risks that their models pose. While some have allowed third-party auditors to evaluate the model for risks, there is much more progress to be made.
The undersigned parties call upon AI labs to publicly disclose detailed information* about the training, capabilities, risks, and limitations of their AI products. This means disclosing when the language models powering products like ChatGPT are changed or modified, as well as disclosing what the goals and effects of those changes are. It also entails allowing third-party auditors to examine frontier AI models for bias, deception, and other dangerous capabilities.
* We presently don’t insist upon sharing model weights due to the potential for dangerous misuse.